Built 26/04/17 09:39commit 8de3d61
中文 | English
Ralph Wiggum 如何从《辛普森一家》角色变成当下 AI 领域最响亮的名字之一 - Venture Beat
看这个视频可以看到实操并理解它的理论;如果想更深入,继续往下读。
看这个视频可以了解为什么 claude code plugin 不是答案 🤝
😎
这里有一份挺有意思的现场报告,记录了在一次 Y Combinator 黑客松活动中,他们如何测试 Ralph Wiggum。
“我们把一个编码 agent 放进 while 循环里,它一夜之间交付了 6 个仓库”
https://github.com/repomirrorhq/repomirror/blob/main/repomirror.md
如果你最近看过我的社交媒体,大概会看到我一直在谈 Ralph,也可能会疑惑 Ralph 到底是什么。Ralph 是一种技术。就其最纯粹的形式而言,Ralph 就是一个 Bash 循环。
while :; do cat PROMPT.md | claude-code ; done对大多数公司的绿地项目来说,Ralph 可以取代绝大多数外包。它当然有缺陷,但这些缺陷是可识别、可通过不同风格 prompt 去修复的。
这正是 Ralph 的美:它是在一个非确定性世界里刻意保持“确定地糟糕”的技术。
任何不会限制 tool calls 和用量的工具都可以用来做 Ralph。
Ralph 目前正在构建一门全新的编程语言。我们已经走到了最后一段路,很快就会发布一门全新的、可用于生产的 esoteric programming language。对我来说很夸张的一点是,Ralph 不但能把这门语言造出来,还能用这门语言继续编程,尽管这门语言并不存在于 LLM 的训练数据里。
用 Ralph 构建软件需要很强的信念,以及一种“最终一致性”的信仰。Ralph 会考验你。每当 Ralph 在构建 CURSED 时走偏,我从来不会怪工具;我会先反过来看自己。每当 Ralph 做出糟糕的事,我就继续调它,像调一把吉他那样。
一开始它什么 playground 都没有,你只给它指令让它自己搭一个。
Ralph 很擅长搭 playground,但它也会满身是伤地回来,因为它会从滑梯上摔下来。这时你就需要继续调它,比如在滑梯旁边立一块牌子写上“滑下去,不要跳,先看周围”,这样 Ralph 就更有可能注意到这块牌子。

看这个视频可以看到实操并理解它的理论;如果想更深入,继续往下读。
最终,Ralph 会满脑子都是这些“提示牌”。这时你就会得到一个不再像 Ralph 那么缺陷明显的新 Ralph。
我在旧金山的时候,教过一些非常聪明的人用 Ralph。有一位特别厉害的工程师听完以后,就把 Ralph 用在了他的下一份合同工作里,收获了极其夸张的 ROI。现在,他们脑子里想的也全都是 Ralph。
prompt.md 里到底写什么?我能拿到吗?
编程社区似乎对“完美 prompt”有一种执念。但完美 prompt 其实并不存在。
你当然可能会想直接拿 CURSED 的 prompt 来用,但如果你不知道怎么驾驭它,它并不会有意义。你就算逐字照搬,大概率也得不到同样的结果,因为这个 prompt 是在持续观察 LLM 行为的基础上不断调出来的。当 CURSED 在构建时,我会一直盯着输出流,看哪里出现了坏行为模式,再把这些地方转化成新的 Ralph 调优点。
先讲几个基本原则
我在旧金山的时候,大家似乎都在试图破解 multi-agent、agent-to-agent communication 和 multiplexing。现阶段,这些都还不是必需品。想想 microservices 以及它带来的那些复杂度。然后再想象一下:如果 microservices(也就是 agents)本身还是非确定性的,那会变成怎样的一团火热混乱。
microservices 的反面是什么?单体应用。一个垂直扩展的单一操作系统进程。Ralph 就是单体的。Ralph 以单进程方式在单个仓库里自主工作,每次循环只做一件事。
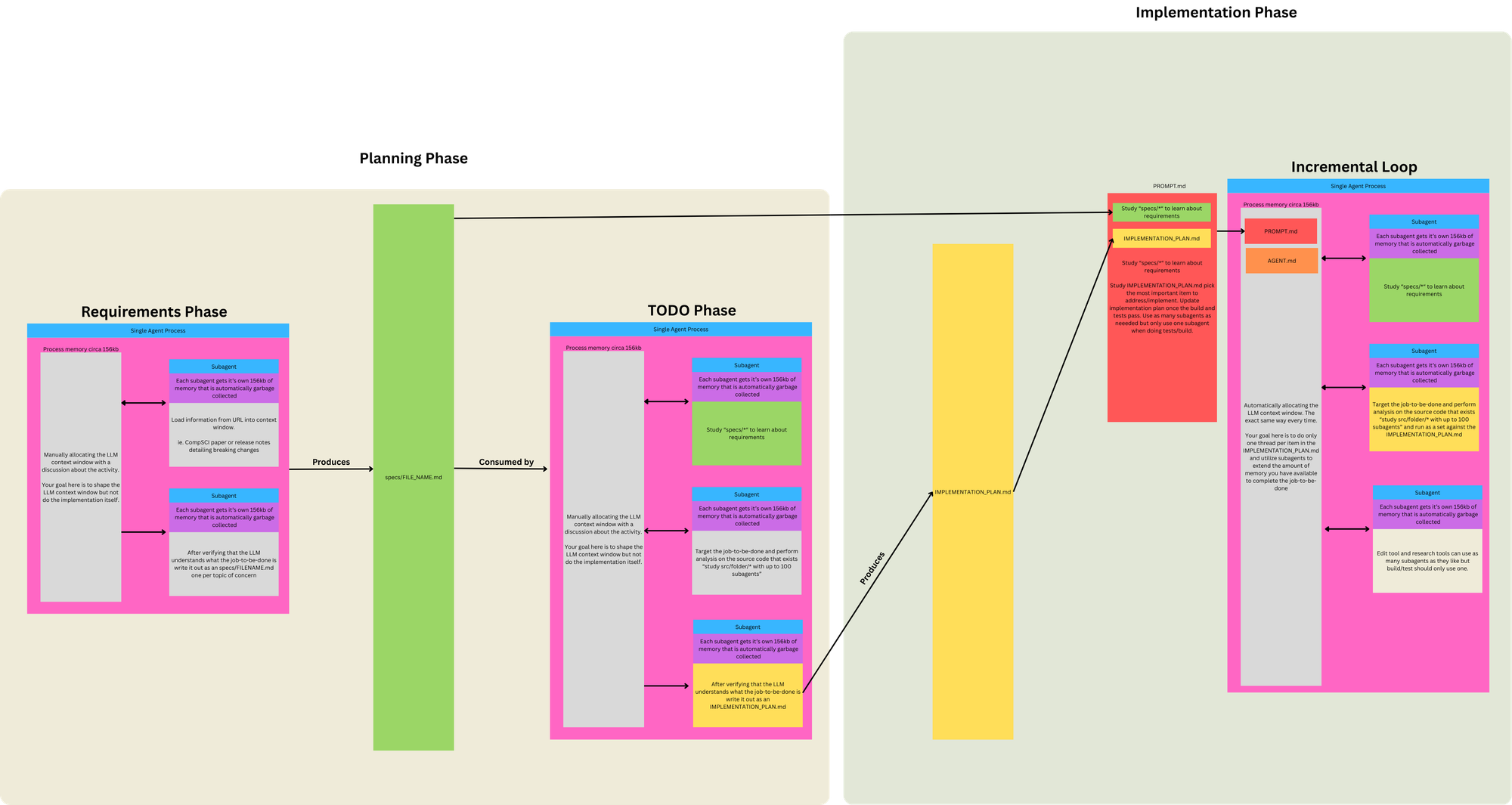
ralph wiggum technique 的示意图
如果你想让 Ralph 给出好结果,就必须要求它每轮只做一件事。只能做一件事。 这听起来也许很疯狂,但你还必须信任 Ralph,让它自己决定哪一件事最重要。这是一种彻底 hands-off 的 vibe coding,会不断挑战你对“负责任工程”的边界认知。
LLM 在判断“现在最重要的是什么”和“下一步应该做什么”这件事上,其实意外地很强。
Your task is to implement missing stdlib (see @specs/stdlib/*) and compiler functionality and produce an compiled application in the cursed language via LLVM for that functionality using parrallel subagents. Follow the @fix_plan.md and choose the most important thing.
上面这个 prompt 里有几个点,我稍后会展开讲;但另一件关键事情是:每一轮都要用同样的方式、确定性地把上下文栈重新分配好。

看这个视频可以看到实操并理解它的理论;如果想更深入,继续往下读。
每轮你都应该重新分配到上下文里的东西,是你的计划(@fix_plan.md)和你的 specifications。下面我会解释一下,如果你还不熟 specs 是什么。
Specs 是在项目早期通过与 agent 的对话形成的。你不应该一开始就让 agent 直接实现整个项目,而是应该先和 LLM 长时间讨论你准备实现的需求。一旦 agent 对任务有了足够好的理解,你再让它把规格写出来,每份规格一个文件,放进 specifications 目录。
每轮只做一件事
每轮一件事。我需要在这里再重复一遍:每轮只做一件事。随着项目推进,你可以适当放宽这个限制;但如果事情开始脱轨,就要立刻把范围重新收窄到只剩一件事。
这个游戏的关键在于,你大约只有 170k 左右的上下文窗口可用。所以必须尽量少用它。你使用得越多,结果就越差。是的,这会显得浪费,因为你等于每一轮都在重复消耗规格文档的那部分上下文,而没有复用它。
扩展上下文窗口
Agentic loop 的工作方式,是执行一个工具,然后评估这个工具的结果。这个评估结果会继续向主上下文窗口中追加新的 allocation。如下所示。
Ralph 要求你换一种思维方式:不要把分配都塞进主上下文窗口。相反,你应该生成 subagents。主上下文窗口应该像一个调度器,只负责调度其他 subagents 去完成那些昂贵的 allocation 型工作,比如总结测试套件是否通过。
Your task is to implement missing stdlib (see @specs/stdlib/*) and compiler functionality and produce an compiled application in the cursed language via LLVM for that functionality using parrallel subagents. Follow the fix_plan.md and choose the most important thing. Before making changes search codebase (don't assume not implemented) using subagents. You may use up to parrallel subagents for all operations but only 1 subagent for build/tests of rust.
你还要意识到,subagents 的并行度是可以控制的。
84 个 squee(claude subagents)在追逐
如果你把几百个 subagents 一起扇出去,再让它们都去 build 和 test 一个应用,那你得到的会是非常糟糕的 back pressure。所以上面的指令才会强调:验证阶段只能用一个 subagent;但 Ralph 在搜索文件系统和写文件这类工作上,可以使用尽可能多的 subagents。
不要假设它还没实现
这些 coding agents 工作的底层方式基本都是 ripgrep,而理解这一点很重要,因为代码搜索本身也可能是非确定性的。
Ralph 的一个常见失败场景是:LLM 跑了 ripgrep,然后错误地得出“这个功能还没实现”的结论。这个失败场景其实很容易修复,只要你给 Ralph 立一块牌子,明确告诉它不要做这种假设。
Before making changes search codebase (don't assume an item is not implemented) using parrallel subagents. Think hard.
如果你醒来发现 Ralph 正在做多套重复实现,那就说明你需要继续调这个步骤。这种非确定性正是 Ralph 的 Achilles' heel。
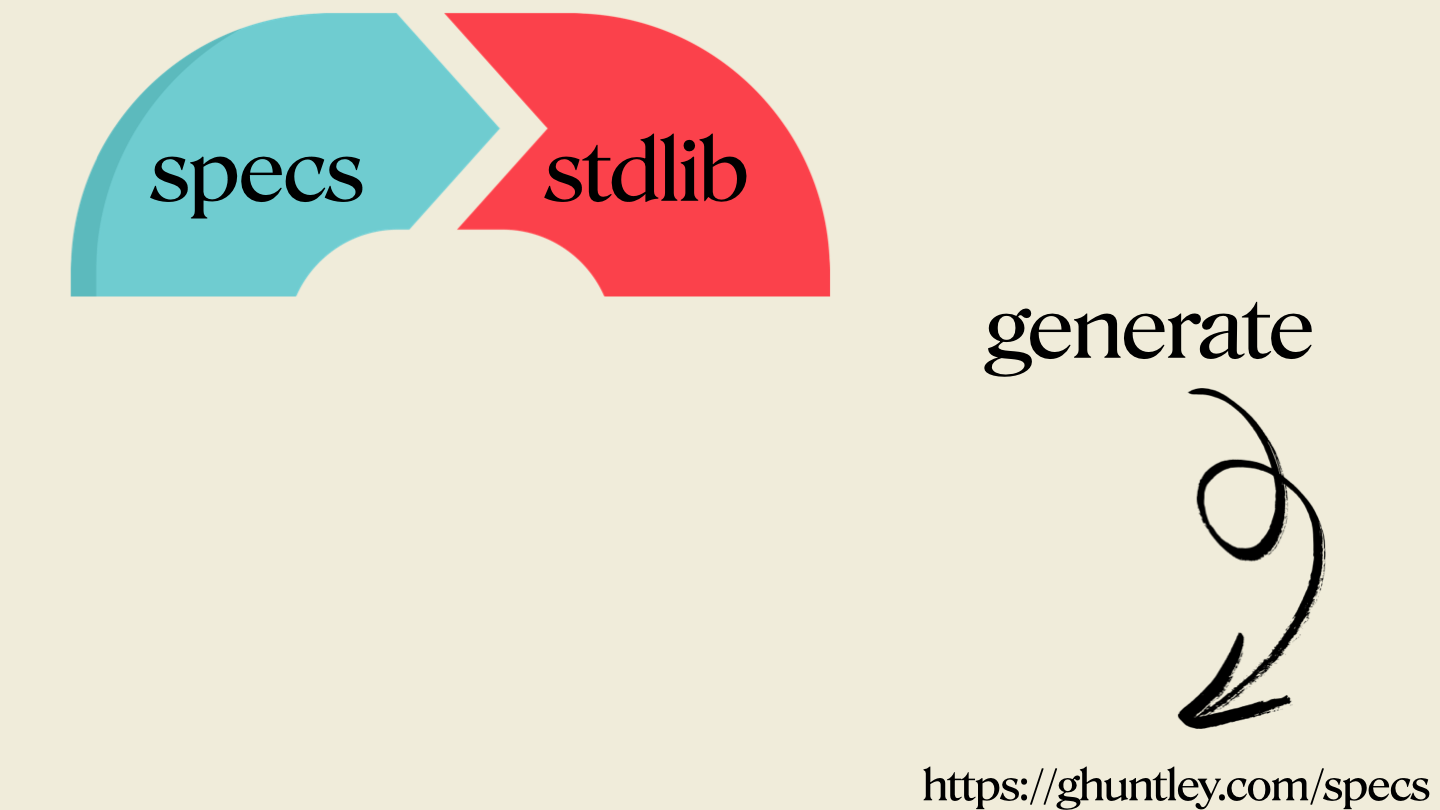
第一阶段:生成
现在生成代码已经很便宜了,而 Ralph 生成什么代码,其实完全受你的技术标准库和 specs 控制。
看这个视频可以看到实操并理解它的理论;如果想更深入,继续往下读。
如果 Ralph 生成了错误的代码,或者用了错误的技术模式,那你就应该更新你的标准库,引导它改用正确模式。
如果 Ralph 根本在构建完全错误的东西,那问题可能出在你的 specifications 上。构建 CURSED 时,我学到的一个惨痛教训是:整整过了一个月,我才发现 lexer 的 specification 里把某个 keyword 在两个相反场景下定义了两次,结果白白浪费了大量时间。Ralph 确实干了很多蠢事,但怪工具其实很容易,真正该怪的是操作者自己。
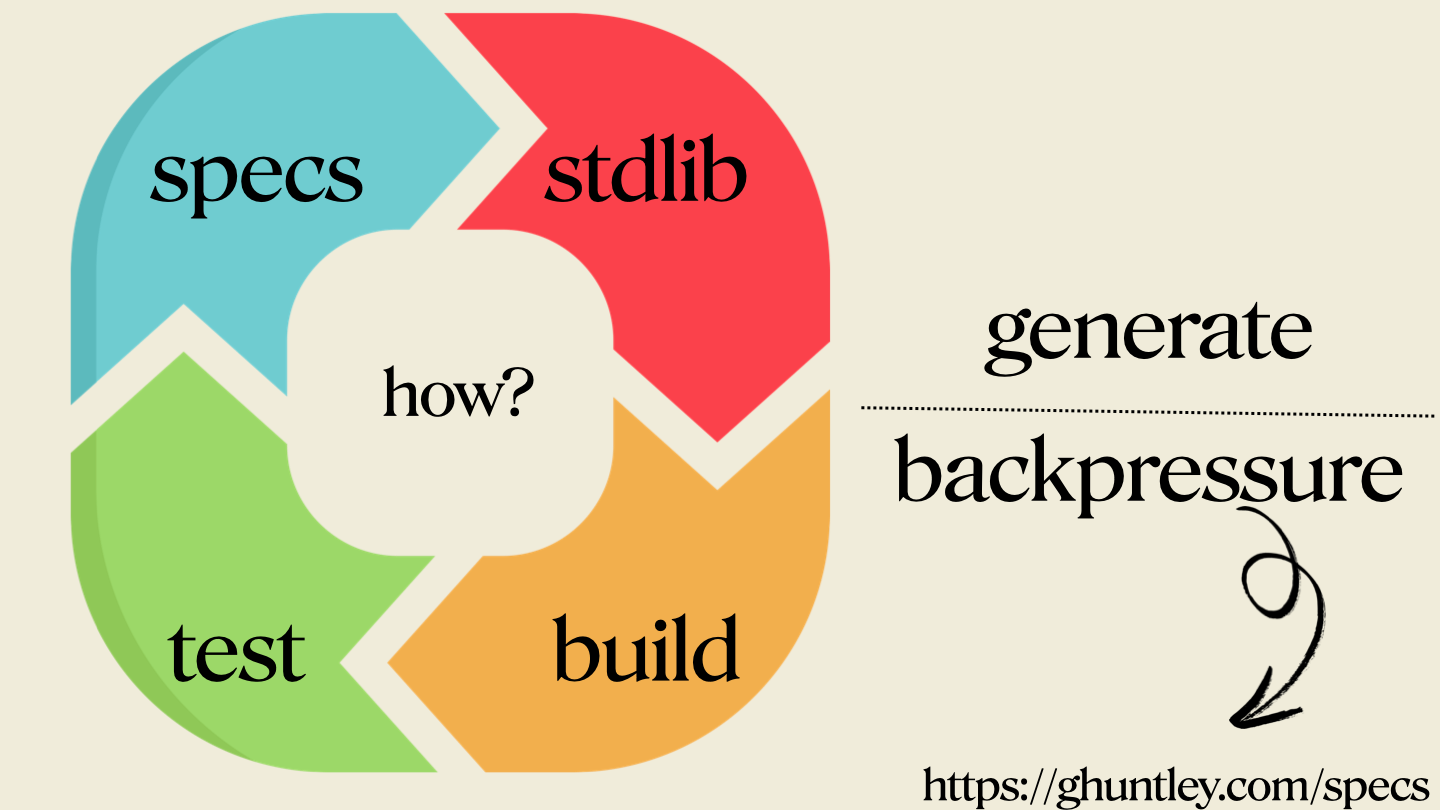
第二阶段:反压
看这个视频可以看到实操并理解它的理论;如果想更深入,继续往下读。
这时你就必须戴上工程师的帽子了。代码生成已经很容易,难的是确保 Ralph 生成的是对的东西。某些编程语言天然就有自己的 back pressure,比如类型系统。
你可能会想:“Rust!它有最好的类型系统。” 但 Rust 的一个现实问题是编译速度慢。而真正重要的是轮子转动的速度,要在这个速度和正确性之间取得平衡。
用什么语言,需要实验。因为我在构建一个编译器,所以我想要极高的正确性,这意味着我选择了 Rust;但这样一来,构建速度就会更慢。这些 LLM 并不擅长一次就生成完美的 Rust 代码,因此它们需要反复尝试更多次。
这件事既可能是优点,也可能是缺点。
上面的图里只写了 “test and build”,但真正需要你戴上工程师帽子的就在这里。任何东西都可以被接进来,作为拒绝无效代码生成的 back pressure。它可以是安全扫描器,也可以是静态分析器,或者任何其他机制。但总的关键点是,这个轮子必须转得足够快。
在构建 CURSED 的过程中,我一直反复使用下面这句 prompt。每次做完改动后,只运行当前那一小块被实现或改进的代码所对应的测试。
After implementing functionality or resolving problems, run the tests for that unit of code that was improved.
如果你用的是动态类型语言,我必须强调:在 Ralphing 时一定要接入静态分析器或类型检查器,例如:
否则,你会得到一场火海般的结果。
在当下记录测试的重要性
当你让 Ralph 通过写测试来施加 back pressure 时,因为 Ralph 每轮只做一件事,而且每轮都是全新上下文,所以在那个当下要求 Ralph 把测试的意义和重要性写出来,是非常关键的。
Important: When authoring documentation (ie. rust doc or cursed stdlib documentation) capture the why tests and the backing implementation is important.
在实现中,大概会长成这样。对我来说,这像是在给未来几轮 LLM 留小纸条,解释为什么这个测试存在、它的重要性是什么,因为未来的循环并不会拥有当时那轮推理的上下文。
defmodule Anole.Database.QueryOptimizerTest do
@moduledoc """
Tests for the database query optimizer.
These tests verify the functionality of the QueryOptimizer module, ensuring that
it correctly implements caching, batching, and analysis of database queries to
improve performance.
The tests use both real database calls and mocks to ensure comprehensive coverage
while maintaining test isolation and reliability.
"""
use Anole.DataCase
import ExUnit.CaptureLog
import Ecto.Query
import Mock
alias Anole.Database.QueryOptimizer
alias Anole.Repo
alias Anole.Tenant.Isolator
alias Anole.Test.Factory
# Set up the test environment with a tenant context
setup do
# Create a tenant for isolation testing
tenant = Factory.insert(:tenant)
# Ensure the optimizer is initialized
QueryOptimizer.init()
# Return context
{:ok, %{tenant: tenant}}
end
describe "init/0" do
@doc """
Tests that the QueryOptimizer initializes the required ETS tables.
This test ensures that the init function properly creates the ETS tables
needed for caching and statistics tracking. This is fundamental to the
module's operation.
"""
test "creates required ETS tables" do
# Clean up any existing tables first
try do :ets.delete(:anole_query_cache) catch _:_ -> :ok end
try do :ets.delete(:anole_query_stats) catch _:_ -> :ok end
# Call init
assert :ok = QueryOptimizer.init()
# Verify tables exist
assert :ets.info(:anole_query_cache) != :undefined
assert :ets.info(:anole_query_stats) != :undefined
# Verify table properties
assert :ets.info(:anole_query_cache, :type) == :set
assert :ets.info(:anole_query_stats, :type) == :set
end
end我发现这能帮助 LLM 判断某个测试是否已不再相关,或者它是否仍然重要,从而影响它是删除、修改还是修复一个测试失败。
不许作弊
Claude 天生倾向于做最小实现和 placeholder 实现。所以在 CURSED 的开发过程中,我会在不同阶段加入下面这种 prompt 变体。
After implementing functionality or resolving problems, run the tests for that unit of code that was improved. If functionality is missing then it's your job to add it as per the application specifications. Think hard.
If tests unrelated to your work fail then it's your job to resolve these tests as part of the increment of change.
9999999999999999999999999999. DO NOT IMPLEMENT PLACEHOLDER OR SIMPLE IMPLEMENTATIONS. WE WANT FULL IMPLEMENTATIONS. DO IT OR I WILL YELL AT YOU
如果在早期 Ralph 还是无视这块牌子,继续做 placeholder 实现,也不用灰心。模型被训练去追逐它们的 reward function,而 reward function 往往是“代码能编译”。你总可以跑更多 Ralph,让它们去识别 placeholder 和最小实现,再把这些问题变成未来循环的待办事项。
TODO 列表
说到这里,下面是我过去几周用来构建 TODO list 的 prompt 栈。这也正是我说 Ralph 会考验你的地方。你必须相信最终一致性,并且知道大多数问题都能通过继续跑更多 Ralph loops 来解决,重点盯住 Ralph 犯错的区域。
study specs/* to learn about the compiler specifications and fix_plan.md to understand plan so far.
The source code of the compiler is in src/*
The source code of the examples is in examples/* and the source code of the tree-sitter is in tree-sitter/*. Study them.
The source code of the stdlib is in src/stdlib/*. Study them.
First task is to study @fix_plan.md (it may be incorrect) and is to use up to 500 subagents to study existing source code in src/ and compare it against the compiler specifications. From that create/update a @fix_plan.md which is a bullet point list sorted in priority of the items which have yet to be implemeneted. Think extra hard and use the oracle to plan. Consider searching for TODO, minimal implementations and placeholders. Study @fix_plan.md to determine starting point for research and keep it up to date with items considered complete/incomplete using subagents.
Second task is to use up to 500 subagents to study existing source code in examples/ then compare it against the compiler specifications. From that create/update a fix_plan.md which is a bullet point list sorted in priority of the items which have yet to be implemeneted. Think extra hard and use the oracle to plan. Consider searching for TODO, minimal implementations and placeholders. Study fix_plan.md to determine starting point for research and keep it up to date with items considered complete/incomplete.
IMPORTANT: The standard library in src/stdlib should be built in cursed itself, not rust. If you find stdlib authored in rust then it must be noted that it needs to be migrated.
ULTIMATE GOAL we want to achieve a self-hosting compiler release with full standard library (stdlib). Consider missing stdlib modules and plan. If the stdlib is missing then author the specification at specs/stdlib/FILENAME.md (do NOT assume that it does not exist, search before creating). The naming of the module should be GenZ named and not conflict with another stdlib module name. If you create a new stdlib module then document the plan to implement in @fix_plan.md
最终,Ralph 会把 TODO list 跑空。或者它会彻底跑偏。毕竟它叫 Ralph Wiggum。到了这个阶段,就进入“品味判断”了。在构建 CURSED 的过程中,我删掉 TODO list 已经不止一次。TODO list 是我会像鹰一样盯着看的东西,而我也会经常把它整个扔掉。
如果我把 TODO list 扔掉了,你可能会问:“那它怎么知道下一步做什么?” 其实很简单。你再跑一个 Ralph loop,显式要求它像上面那样重新生成一份新的 TODO list。
当你拿到新的 todo list 之后,就再次启动 Ralph,只不过这次给它的是从 planning mode 切回 building mode 的指令……
回环是一切
你要尽可能以能让 Ralph 把自己送回 LLM 里做评估的方式去编程。这极其重要。永远去寻找“让 Ralph 回环到自己身上”的机会。这可以很简单,比如让它加更多日志;或者在编译器场景下,让 Ralph 去编译应用,再去观察 LLVM IR 表示。
You may add extra logging if required to be able to debug the issues.
ralph 能把自己送进大学
@AGENT.md 是这个循环的核心。它定义了 Ralph 应该如何编译和运行项目。如果 Ralph 发现了新的经验,就允许它自我改进:
When you learn something new about how to run the compiler or examples make sure you update @AGENT.md using a subagent but keep it brief. For example if you run commands multiple times before learning the correct command then that file should be updated.
在循环中,Ralph 可能会判断某些东西需要修复。把这种判断记录下来至关重要。
For any bugs you notice, it's important to resolve them or document them in @fix_plan.md to be resolved using a subagent even if it is unrelated to the current piece of work after documenting it in @fix_plan.md
你会在早上醒来时看到一个坏掉的代码库
是的,这是真的。你有时会醒来,发现代码库已经坏到编译不过了,而且 Ralph 也修不好。这时候你就得自己开脑子做判断。是直接 git reset --hard 然后把 Ralph 再启动一遍更划算?还是你需要想出另一组 prompt 去把 Ralph 救回来?
When the tests pass update the @fix_plan.md`, then add changed code and @fix_plan.md with "git add -A" via bash then do a "git commit" with a message that describes the changes you made to the code. After the commit do a "git push" to push the changes to the remote repository.
As soon as there are no build or test errors create a git tag. If there are no git tags start at 0.0.0 and increment patch by 1 for example 0.0.1 if 0.0.0 does not exist.
我记得在最开始把这个编译器跑起来的时候,编译错误多到能把 Claude 的上下文窗口都塞满。于是我当时做的事情是,把那份编译错误文件扔给 Gemini,让 Gemini 帮 Ralph 出一份计划。
但可维护性呢?
每次我听到这个问题,我都会反问一句:“被谁维护?” 被人类吗?为什么我们还要把“可维护性”的参照系放在人类身上?难道现在不是 post-AI 阶段了吗?需要适配时,你直接继续跑 loop 来修复和调整不就行了?😎
任何由 AI 制造出来的问题,都能通过另一组 prompt 解决
这也把我带到另一个点。如果你想调皮一点,可能已经能在 GitHub 上找到 CURSED 的代码库。我只想请你别把它发到社交媒体上,因为它还没准备好发布。我想先把这东西调到一个程度,让我们能够无可辩驳地证明:AI 不但可以构建一门全新的编程语言,而且能在训练数据中完全没有这门语言的情况下继续用它编程。
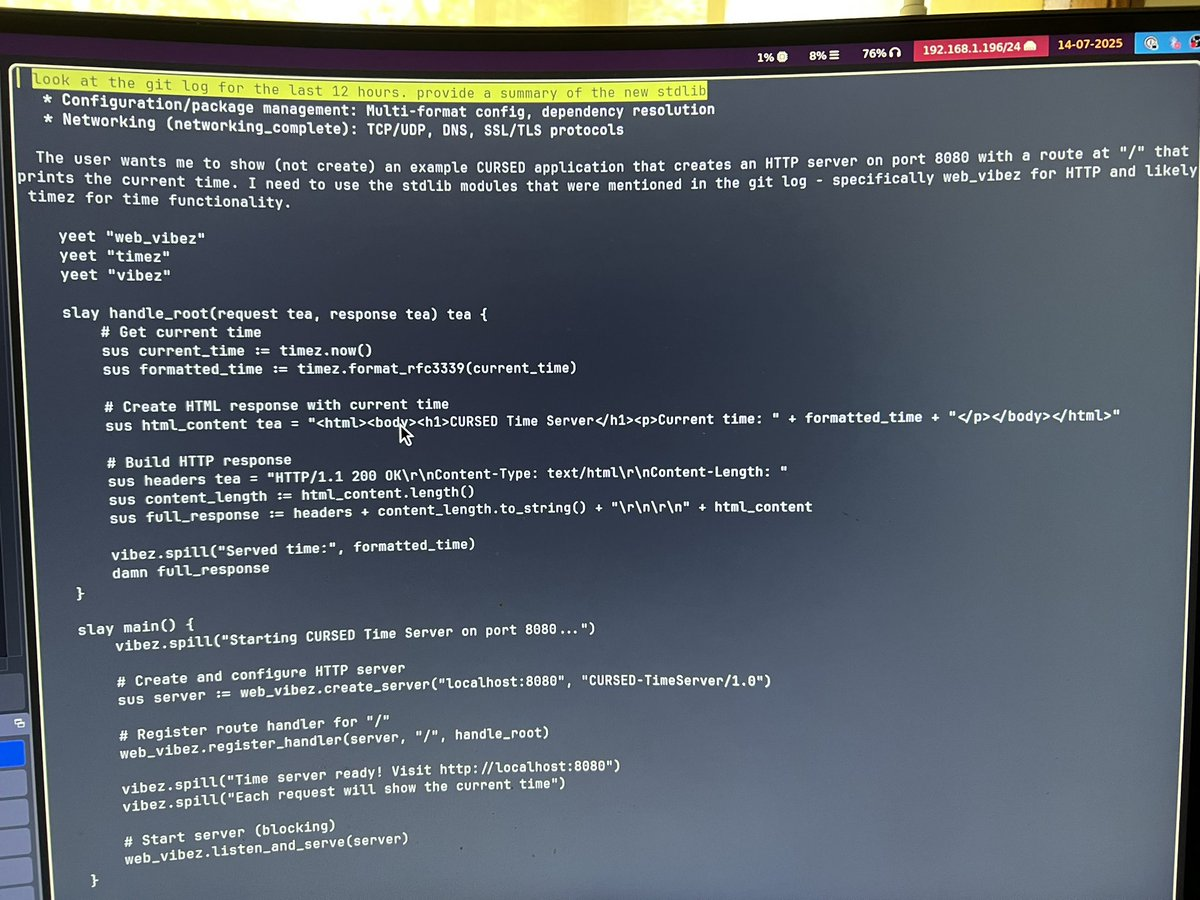
cursed 作为一个 webserver
我真正希望大家理解的是:所有这些由 Ralph 造成的问题,都可以通过设计另一套 prompt,再继续跑更多 Ralph loops 来解决。
我预期 CURSED 仍然会有很多明显缺口,就像 Ralph Wiggum 自己一样。现在这个阶段,要挑 CURSED 的毛病实在太容易了,这也是我一直没发布这篇文章的原因。仓库里到处都是垃圾、临时文件和二进制产物。
Ralph 有三种状态:半生不熟、烤熟了、以及“烤熟了但带着一些未指定的潜在行为”(而这些潜在行为有时候还挺不错!)
当 CURSED 发布时,请理解一点:它是 Ralph 构建的。至于下一步在技术上的演化,我认为已经不会再是 Ralph 本身了。我依然强烈认为,只要模型和工具还维持现在这种状态,我们已经处在 post-AGI 领域。你真正需要的只是 tokens;这些模型渴望 tokens,所以就不断喂给它们。如果你采用正确的方法,你就已经拥有了自动化软件开发的基础原语。
尽管如此,工程师仍然是必须的。没有资深工程能力在旁边引导 Ralph,这件事根本不可能成立。任何声称工程师已经不再需要、工具可以 100% 独立完成全部工作的说法,都是在胡扯。
不过,Ralph 这套技术确实已经惊人地有效,足以在绿地项目场景里替代当前大多数软件工程师的大部分工作。
最后我想说一句:
“我绝不会把 Ralph 用在一个既有代码库里。”
不过,如果你真去试了,我会很想知道结果是什么。它最适合作为一种绿地项目的启动技术,预期是你能用它跑到大约 90% 的完成度。
当前用于构建 CURSED 的 prompt
下面是 Ralph 当前用来构建 CURSED 的 prompt。
0a. study specs/* to learn about the compiler specifications
0b. The source code of the compiler is in src/
0c. study fix_plan.md.
1. Your task is to implement missing stdlib (see @specs/stdlib/*) and compiler functionality and produce an compiled application in the cursed language via LLVM for that functionality using parrallel subagents. Follow the fix_plan.md and choose the most important 10 things. Before making changes search codebase (don't assume not implemented) using subagents. You may use up to 500 parrallel subagents for all operations but only 1 subagent for build/tests of rust.
2. After implementing functionality or resolving problems, run the tests for that unit of code that was improved. If functionality is missing then it's your job to add it as per the application specifications. Think hard.
2. When you discover a parser, lexer, control flow or LLVM issue. Immediately update @fix_plan.md with your findings using a subagent. When the issue is resolved, update @fix_plan.md and remove the item using a subagent.
3. When the tests pass update the @fix_plan.md`, then add changed code and @fix_plan.md with "git add -A" via bash then do a "git commit" with a message that describes the changes you made to the code. After the commit do a "git push" to push the changes to the remote repository.
999. Important: When authoring documentation (ie. rust doc or cursed stdlib documentation) capture the why tests and the backing implementation is important.
9999. Important: We want single sources of truth, no migrations/adapters. If tests unrelated to your work fail then it's your job to resolve these tests as part of the increment of change.
999999. As soon as there are no build or test errors create a git tag. If there are no git tags start at 0.0.0 and increment patch by 1 for example 0.0.1 if 0.0.0 does not exist.
999999999. You may add extra logging if required to be able to debug the issues.
9999999999. ALWAYS KEEP @fix_plan.md up to do date with your learnings using a subagent. Especially after wrapping up/finishing your turn.
99999999999. When you learn something new about how to run the compiler or examples make sure you update @AGENT.md using a subagent but keep it brief. For example if you run commands multiple times before learning the correct command then that file should be updated.
999999999999. IMPORTANT DO NOT IGNORE: The standard libray should be authored in cursed itself and tests authored. If you find rust implementation then delete it/migrate to implementation in the cursed language.
99999999999999. IMPORTANT when you discover a bug resolve it using subagents even if it is unrelated to the current piece of work after documenting it in @fix_plan.md
9999999999999999. When you start implementing the standard library (stdlib) in the cursed language, start with the testing primitives so that future standard library in the cursed language can be tested.
99999999999999999. The tests for the cursed standard library "stdlib" should be located in the folder of the stdlib library next to the source code. Ensure you document the stdlib library with a README.md in the same folder as the source code.
9999999999999999999. Keep AGENT.md up to date with information on how to build the compiler and your learnings to optimise the build/test loop using a subagent.
999999999999999999999. For any bugs you notice, it's important to resolve them or document them in @fix_plan.md to be resolved using a subagent.
99999999999999999999999. When authoring the standard library in the cursed language you may author multiple standard libraries at once using up to 1000 parrallel subagents
99999999999999999999999999. When @fix_plan.md becomes large periodically clean out the items that are completed from the file using a subagent.
99999999999999999999999999. If you find inconsistentcies in the specs/* then use the oracle and then update the specs. Specifically around types and lexical tokens.
9999999999999999999999999999. DO NOT IMPLEMENT PLACEHOLDER OR SIMPLE IMPLEMENTATIONS. WE WANT FULL IMPLEMENTATIONS. DO IT OR I WILL YELL AT YOU
9999999999999999999999999999999. SUPER IMPORTANT DO NOT IGNORE. DO NOT PLACE STATUS REPORT UPDATES INTO @AGENT.md当前用于规划 CURSED 的 prompt
study specs/* to learn about the compiler specifications and fix_plan.md to understand plan so far.
The source code of the compiler is in src/*
The source code of the examples is in examples/* and the source code of the tree-sitter is in tree-sitter/*. Study them.
The source code of the stdlib is in src/stdlib/*. Study them.
First task is to study @fix_plan.md (it may be incorrect) and is to use up to 500 subagents to study existing source code in src/ and compare it against the compiler specifications. From that create/update a @fix_plan.md which is a bullet point list sorted in priority of the items which have yet to be implemeneted. Think extra hard and use the oracle to plan. Consider searching for TODO, minimal implementations and placeholders. Study @fix_plan.md to determine starting point for research and keep it up to date with items considered complete/incomplete using subagents.
Second task is to use up to 500 subagents to study existing source code in examples/ then compare it against the compiler specifications. From that create/update a fix_plan.md which is a bullet point list sorted in priority of the items which have yet to be implemeneted. Think extra hard and use the oracle to plan. Consider searching for TODO, minimal implementations and placeholders. Study fix_plan.md to determine starting point for research and keep it up to date with items considered complete/incomplete.
IMPORTANT: The standard library in src/stdlib should be built in cursed itself, not rust. If you find stdlib authored in rust then it must be noted that it needs to be migrated.
ULTIMATE GOAL we want to achieve a self-hosting compiler release with full standard library (stdlib). Consider missing stdlib modules and plan. If the stdlib is missing then author the specification at specs/stdlib/FILENAME.md (do NOT assume that it does not exist, search before creating). The naming of the module should be GenZ named and not conflict with another stdlib module name. If you create a new stdlib module then document the plan to implement in @fix_plan.md